UQLMを用いたハルシネーションの検出
この評価手法を、実務で使いこなせますか?
生成AIのハルシネーション検知や品質管理の具体的な手法を学ぶ、短期集中プログラムを展開中。理論だけでなく、実務ですぐに使えるスキルを習得できます。
はじめに
近年、ChatGPTをはじめとする生成AIを業務やサービスに組み込むケースが急増しています。
しかし、実際に導入・開発・運用を進める中で次のような悩みを感じたことはないでしょうか。
- 生成AIの出力結果をどう評価すればいいのかわからない
- 出力結果にハルシネーションが含まれているかを把握したい
- 精度評価を行いたいが、正解データの作成にコストがかかる
本記事では、正解データなしで不確実性を定量化できる UQLM というライブラリを用いて、これらの問題を解決するアプローチについて紹介します。
UQLMとは?
UQLMは、正解データを必要とせずにLLMの出力結果の不確実性を評価するためのPythonライブラリです。
従来、生成AIの精度を評価するには正解となるデータが必要でした。
しかし、生成AIの出力は自由度が高く、唯一の正解が存在しないケースも多いため、正解データの作成には多大なコストと時間がかかるという課題があります。
UQLMは正解データを一切使わずにLLMの出力の信頼性を測定できるため、低コストかつ迅速にモデルの品質を評価することが可能です。
UQLMを用いることで、例えば次のような用途に活用できます。
- ハルシネーション検出の自動化
- モデル改善前後の精度比較
- 自動評価パイプラインの構築
UQLMの評価指標
UQLMでは、出力の不確実性を評価するために、以下の4種類のスコアを提供しています。これらの指標はすべて0~1の値を取り、スコアが高いほどエラーやハルシネーションの可能性が低いことを示します。
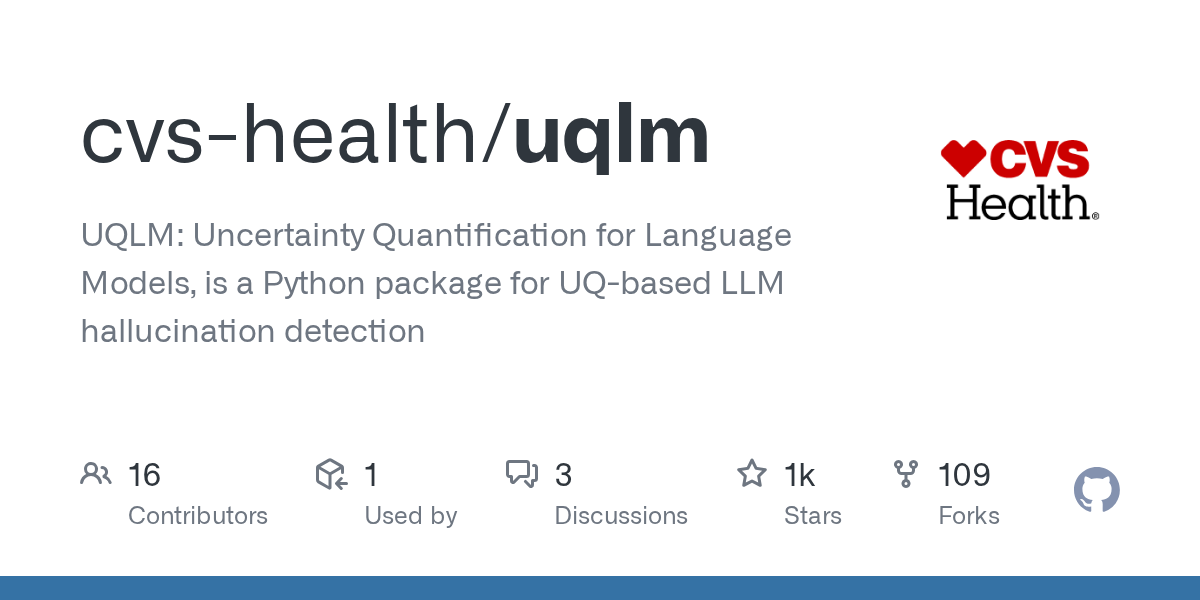
1.Black-Box Scores
同一プロンプトから複数の出力を生成し、その一貫性から不確実性を推定する。内部情報やトークン確率は不要で、あらゆるLLMに適用可能。
2.White-Box Scores
トークン確率を用いて不確実性を推定する。Black-Boxより高速・低コストだが、内部確率へのアクセスが必要なため対応モデルが限定される。

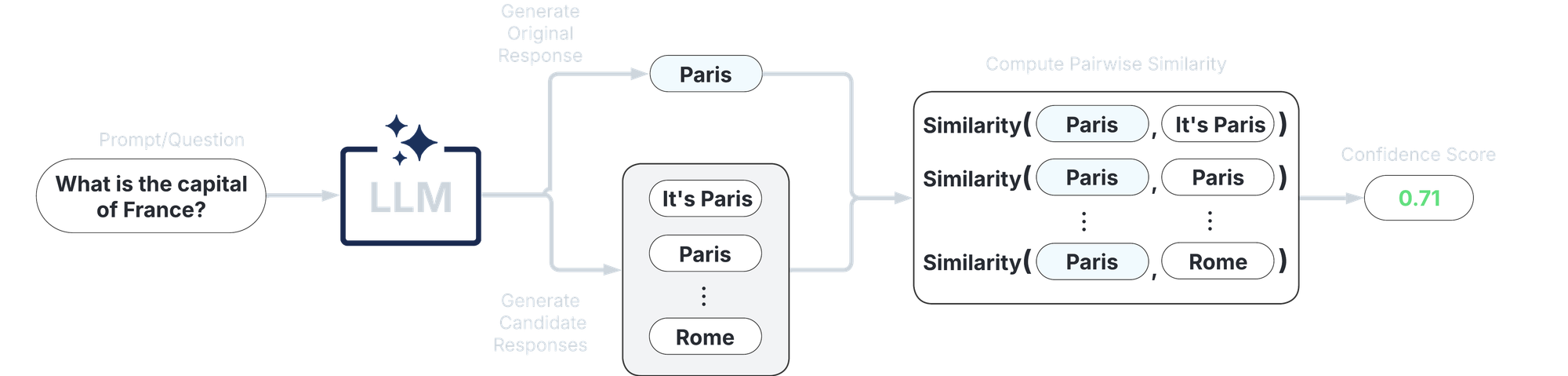
3.LLM-as-a-Judge Scores
別のLLMを審査役として用い、元の出力の妥当性を評価する。プロンプト設計や審査するモデルの選択により高いカスタマイズ性がある。
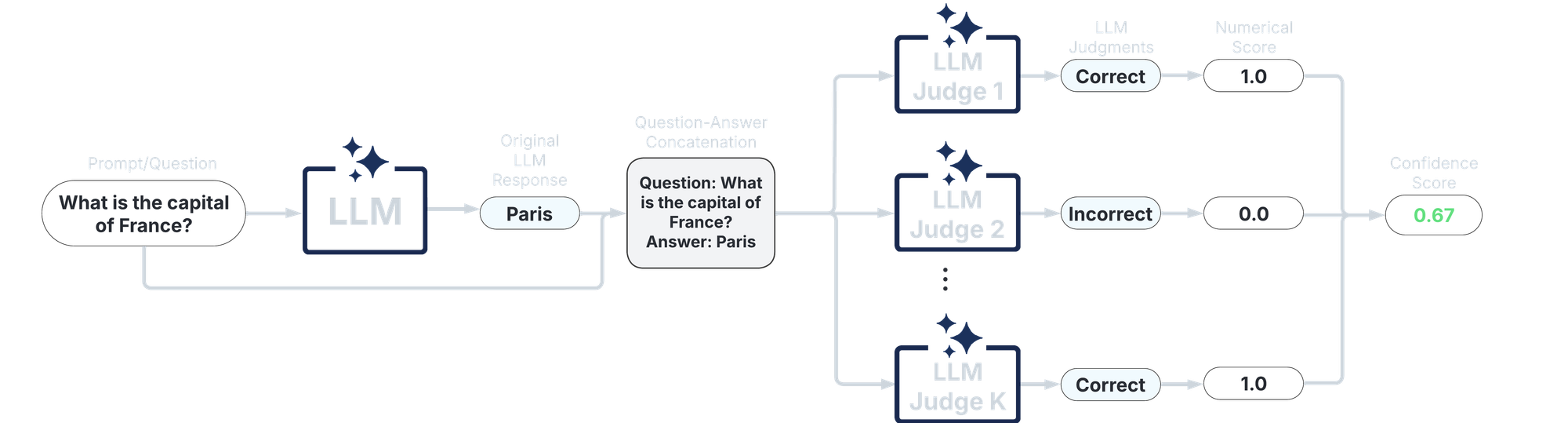
4.Ensemble Scores
複数のスコアを重み付きで統合し、より頑健な不確実性推定を提供する。用途に応じて柔軟に設計できる。
指標の比較
4つの指標をレイテンシ、コスト、互換性の観点から比較すると以下のようになります。
| 指標 | レイテンシ | コスト | 互換性 |
|---|---|---|---|
| Black-Box Scorers |
⌚ 中〜高 (複数の生成と比較) |
💸 高い (複数回のLLM呼び出し) |
🌐 ユニバーサル (様々なLLMで利用可能) |
| White-Box Scorers |
⚡ 最小 (既知のトークン確率を利用) |
✅ なし (追加のLLM呼び出しなし) |
🔒 限定的 (トークン確率へのアクセスが必要) |
| LLM-as-a-Judge Scorers |
⏳ 低〜中 (追加のジャッジコールが必要) |
💰 低〜高 (審査員の数に依存) |
🌐 ユニバーサル (様々なLLMで利用可能) |
| Ensemble Scorers |
♾️ フレキシブル (組み合わせる指標に依存) |
♾️ フレキシブル (組み合わせる指標に依存) |
♾️ フレキシブル (組み合わせる指標に依存) |
UQLMを用いた実装
ここでは、UQLMの インストール方法 と実際に Black-Box Scorersを用いてハルシネーションを検出する例 を紹介します
UQLMのインストール
Python 3.9 以上の環境で、以下のコマンドを実行します。
pip install uqlmハルシネーションの検出例
UQLM の Black-Box Scorersを使って生成結果の一貫性からハルシネーションを推定する方法を紹介します。
Black-Box Scorersでは同じ質問に対する回答のばらつきから不確実性を推定します。
(以下の例では Jupyter Notebookのipynbファイルを使用しています)
- 評価プロンプトの準備
今回は以下の5つのプロンプトの回答にハルシネーションが発生しているかを検証します。
INSTRUCTION = "質問が与えられます。説明なしで、できるだけ簡潔に答えだけを返してください。\n"
QUESTION = [
"アメリカ合衆国の初代大統領は誰ですか?",
"日本の国旗の縦と横の正しい比率は?",
"日本で2番目に高い山の標高は?",
"世界で一番大きい砂漠はどこですか?",
"ローマ数字の「M」から「D」を引くと何ですか?"
]
prompts = [INSTRUCTION + q for q in QUESTION]- 指標のセットアップ
BlackBox Scorersの設定を行います。BlackBoxUQ の引数には、利用する LLM の指定(llm)と、評価に使用する指標(scorers)を指定します。
今回は、回答の意味的一貫性のばらつきを測る semantic_negentropy を使用します。
from langchain_openai import ChatOpenAI
from uqlm import BlackBoxUQ
llm = ChatOpenAI(model="gpt-4o-mini")
# Black-Box Scorersの設定
bbuq = BlackBoxUQ(
llm=llm,
scorers=["semantic_negentropy"]
)- ハルシネーションの推定
質問ごとに 複数の回答(num_responses=5)を生成し、指定したScorer による評価を行います。
# 複数回生成してスコアを算出
results = await bbuq.generate_and_score(prompts=prompts, num_responses=5)
- 結果
DataFrame形式に変換して結果を確認できます。
# DataFrame形式で結果を確認
df = results.to_df()
結果をまとめると以下のようになり、今回の例では0.5を閾値とすることでハルシネーションの検出が行えます。
| 正誤 | 正解 | response | semantic_negentropy |
|---|---|---|---|
| ◯ | ジョージ・ワシントン | ジョージ・ワシントン | 1.00 |
| ◯ | 2:3 | 2:3 | 1.00 |
| × | 3193メートル | 3192メートル。 | 0.31 |
| △ | 南極大陸 | 南極砂漠。 | 0.44 |
| × | D | 「CD」です。 | 0.44 |
まとめ
このように UQLM を使用することで、正解データを準備せずに、回答の一貫性からハルシネーション傾向を推定することが可能 となります。
これによりRAG の性能調査、モデル更新前後の精度比較、社内 GPT の信頼性チェックなどを低コストかつ迅速に行うことが可能となります。
Furious Greenでは、AI技術を「学ぶ」「試す」「使いこなす」ための環境づくりを支援しています。
生成 AI の品質評価や運用に課題をお持ちの方は、ぜひご相談ください。