Google Cloudサービスをフル活用した転倒検知システム
本記事では、クラウドサービス未経験の大学院生2人が、Furious Green合同会社にて1年間インターンを経験し、1年間で学んだことの集大成として、Google Cloudサービスをフル活用した転倒検知システムを開発した際の記録をご紹介します。
はじめに
はじめまして!本記事では、クラウドサービス未経験の大学院生2人が、Furious Green合同会社にて1年間インターンを経験し、1年間で学んだことの集大成として、Google Cloudサービスをフル活用した転倒検知システムを開発した際の記録をご紹介します。
なぜ転倒検知システムなのか
私たちが転倒検知システムを選んだ理由は、高齢化が進む社会において、一人暮らしの高齢者の転倒リスクや、医療・介護現場での人手不足といった課題を解決するためです。
高齢者にとって転倒は頻発する事故の一つであり、適切な対応が遅れると重篤な健康被害につながる可能性があります。しかし、介護・医療現場の人手不足に加え、核家族化の進行により、身近に見守る人がいないケースも増えており、迅速な対応が難しくなっています。
そこで、エッジデバイスとクラウドサービスを組み合わせた転倒検知システムを導入することで、リアルタイムに転倒を検知し、迅速な対応を可能にすると考えました。これにより、高齢者の安全を確保するとともに、介護・医療従事者の負担を軽減することが期待されます。
システム構成
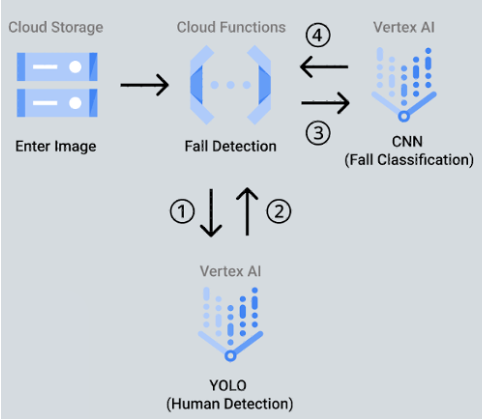
転倒検知システムの構成は以下の通りです。まず、エッジデバイスであるESP32で撮影を行い、クラウド上のストレージに保存します。この保存をトリガーとして転倒検知モデルで転倒可否を判断し、転倒していた場合にはSlackに通知する形としました。

完成イメージ
エッジデバイスで撮影された画像が、転倒していると判断された場合Slackに通知がいきます。

開発フロー
開発フローは、転倒検知システムのクラウドサービス上での実装(システム構成のピンク色の領域)とエッジデバイスでの撮影とクラウドとの接続(システム構成の緑色の領域)の2ステップから成っており、各ステップは以下のように細分化されます。
- 転倒検知システムのクラウドサービス上での実装
- ローカルで転倒検知モデルの作成
- Vertex AI Endpointの作成
- Cloud StorageをトリガーとしたCloud Functionsの作成
- Pub/Subを用いたSlackへの通知
- エッジデバイスでの撮影とクラウドとの接続
- エッジデバイスで撮影
- 画像データの送受信
- mTLS認証
転倒検知システムのクラウドサービス上での実装
まず、転倒検知システム全体をクラウドサービス上でデプロイしました。
ローカル環境で転倒検知モデルの作成
転倒検知において、一般的に用いられているモデルを調査し、まずはローカル環境でのモデル構築に取り組みました。
Kaggleでは「Fall Detection Dataset」とよばれる、様々な人の転倒シーンを含むデータセットが公開されています。まずは、このデータセットの内容や、このデータセットを用いてどのようにして転倒検知のモデルが作成されているかを調査しました。

※ Fall Detection Dataset: https://www.kaggle.com/datasets/uttejkumarkandagatla/fall-detection-dataset
そこで、YOLOとCNNを組み合わせる手法が頻繁に用いられていることが確認できたため、下記のサイトを参考にしながら、モデルの構築に取り組みました。https://www.kaggle.com/code/sahiltarlana2601/fall-detection-final
モデルの詳細については、下記の通りです。
- YOLO
まず、YOLOで画像内の人物を検出し、その座標を特定します。 具体的には、最新の「yolov11n」を用いました。
- CNN
次に、YOLOで検出された人物の画像領域を切り出し、転倒しているかどうかを判定します。ここで、「vgg16」と呼ばれるImageNetという大量の画像のデータセットを学習した事前学習済みモデルを用いました。また、先述の「Fall Detection Dataset」を用いてファインチューニングをし、転倒検知に特化した画像分類モデルの構築を行いました。
Vertex AI Endpointの作成

ローカル環境で作成した転倒検知モデルを、クラウドサービス上にデプロイしました。当初は、Cloud Functionsで直接モデルを実行することを検討しましたが、Cloud Functionsは関数が呼び出されるたびにモデルを読み込む必要があり、処理に時間がかかるという課題がありました。
そこで、事前に学習済みモデルを読み込み、API経由で高速に呼び出すことができるVertex AI Endpointsを利用することにしました。
Vertex AI Endpointsへのデプロイは、以下の手順で実施しました。
- Flaskアプリケーションの作成:モデルをAPIとして公開するためのWebアプリケーションを作成
- コンテナ化:作成したアプリケーションをDockerコンテナにパッケージング
- Artifact Registryへのプッシュ:パッケージングしたコンテナイメージを保管
- Vertex AI Model Registryへのアップロード:モデルの情報を登録
- Vertex AI Endpointへのデプロイ:登録したモデルをエンドポイントとして公開
これらの手順は、それぞれ「アプリケーションの作成」、「設計図の作成」、「設計図の保管」、「設計図の登録」、「アプリケーションの公開」と考えると、イメージしやすいかと思います。
YOLOモデルのデプロイは、”https://medium.com/@oredata-engineering/yolov8-deployment-on-vertex-ai-endpoints-1a79fd1d4ae0” を参考にしました。また、独自に作成したCNNモデルについては、ローカル環境での実装をベースにコードを修正し、デプロイしました。
以上の手順により、転倒検知モデルのクラウド環境へのデプロイが完了しました。
Cloud StorageをトリガーとしたCloud Functionsの作成
Vertex AI EndpointsでモデルをAPIとして公開できたので、このAPIを呼び出す処理を実装する必要がありました。そこで、Cloud Storageへの画像ファイルのアップロードをトリガーとするCloud Functions を作成しました。処理の流れは以下の通りです。
- Cloud Storageにアップロードされた画像ファイルをCloud Functionsが取得
- 取得した画像データをVertex AI Endpointに送信し、転倒検知の推論を実行
- Vertex AI Endpointからの推論結果をCloud Functionsが受信
- 推論結果(転倒の有無)をCloud Storageに保存
Cloud Storageの画像データをCloud Functionsで読み書きする方法は以下の記事を参考にしました。
https://qiita.com/bell_at_ds/items/52a56da7c4605e1068e3
また、Cloud FunctionsでVertex AI Endpointの推論結果を取得するためにはgoogle-cloud-aiplatformライブラリのEndpoint関数を使用しました。
https://cloud.google.com/python/docs/reference/aiplatform/latest/google.cloud.aiplatform.Endpoint
Pub/Subを用いたSlackへの通知
ここまでの実装で、Cloud Storageに追加された画像の転倒検知が可能になったので、転倒が検知された場合にのみ、Slackへ通知する機能を追加します。(下記画像のような機能)
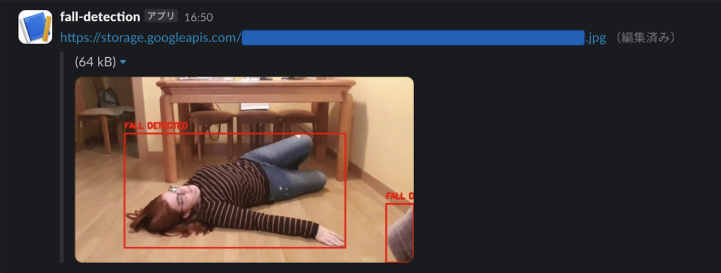
転倒検知有無が判定された画像がCloud Storageに保存されるので、この保存をトリガーとしてPub/Subにパブリッシュします。パブリッシュを受け取ったPub/SubはサブスクライバーであるCloud Run Functionsを起動させ、このCloud Run FunctionsがSlackに通知を送ります。
この構成は下記のサイトを参考に作成しています。
https://techblog.nhn-techorus.com/archives/29845
ここで、私たちがPub/Subを用いた理由としては、今後の拡張性を考慮してSlack以外の通知手段を追加しやすい設計とするためです。
エッジデバイスでの撮影とクラウドとの接続
これまでの実装では、転倒検知を行う画像を手動でCloud Storageにアップロードしていました。毎回手動で画像を追加するのは非効率であり、実用上では問題があります。そこで、エッジデバイスで撮影した画像を自動的にCloud Storageへアップロードする機能を実装します。具体的には、ESP32-WROVERで撮影した画像データをHTTP POSTリクエストをCloud Functionsに送り、Cloud FunctionsからCloud Storageに保存することで、アップロードを実現します。
- エッジデバイスで撮影

まず、エッジデバイスで撮影を行えるようにしました。環境は以下の通りです。
デバイス:ESP32-WROVER
IDE: Thonny
使用言語:MicroPython
エッジデバイスには、カメラ機能を容易に実装できるファームウェア が公開されている ESP32-WROVERを選定しました。開発にあたり、FreenoveのGitHubから提供されているフォームウェアを利用しました。
開発環境には、マイクロコンピュータのプログラミングによく利用されている統合開発環境(IDE)であるThonnyを選びました。
エッジデバイス上で動作するプログラミング言語には、軽量でESP32のようなマイクロコンピュータでの動作に適したMicroPythonを採用しました。MicroPythonは、Pythonの構文をほぼそのまま利用できるため、Pythonの知識があれば容易に開発を始められることから今回使用することにしました。
環境構築とカメラの実装はそれぞれ以下の記事を参考にしています。
Thonnyの環境構築
https://www.greenwich.co.jp/blog-archives/p/32960
カメラの実装
https://github.com/Freenove/Freenove_ESP32_WROVER_Board/blob/main/Python/Python_Tutorial.pdf
- 画像データの送受信
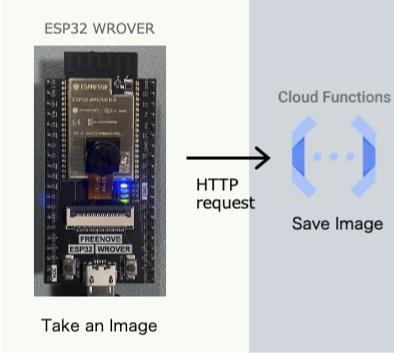
クライアント側であるESP32からCloud Functionsのサーバーに画像データを送信し、サーバー側でその画像をCloud Storageに保存する処理を行います。
クライアント側
- データ形式の変換:画像の取得→画像をbase64にエンコード→JSON形式に変換
- リクエストの送信:urequestsライブラリを用いて、HTTP POSTリクエストを送信します
MicroPythonの構文は基本的にPythonと似ていますが、ライブラリ名が異なったり(例:requests → urequests)、一部ライブラリが含まれていないため、適宜置き換える必要があります。データの送受信方法として、最初はurequestsを使用していましたが、後述するmTLS認証の実装に際しては、usslライブラリを使用するように変更しました。
サーバー側
サーバー側では、Flask を使用して HTTPリクエストを受け取る WebサーバーをCloud Functions上で構築します。リクエストで受け取った画像データをCloud Storageに保存する機能を実装するtことで、クライアントから送信された画像データが自動的にCloud Storageに保存されるようにします。
- mTLS認証

現在の実装では、Cloud FunctionsのURLを知っているだけで、誰でも画像を保存できてしまいます。これを防ぐために、mTLS認証を導入し、認可されたクライアントのみが接続できるようにします。
まず、以下の記事を参考に、opensslを用いてクライアントとサーバーの各種証明書および秘密鍵を準備します。
https://tex2e.github.io/blog/python/mtls
クライアント側
クライアント証明書とクライアント秘密鍵をインストールします。MicroPythonのrequestライブラリではmTLS認証を実装できないので、usslライブラリで実装を行います。実装は、Pythonでのクライアント側処理とMicroPythonのSSLのドキュメントを参考に開発しました。
- Pythonでのクライアント側処理: Python SSLクライアントサイドのドキュメント
- MicroPythonのSSLドキュメント: MicroPython SSLライブラリ
MicroPythonのドキュメントでは、sslという名前で記載されていますが、実際にはusslライブラリとして使用できます。ただし、MicroPythonのusslライブラリではサーバー証明書の検証が行えないという制約がある点に注意が必要です。サーバー側サーバー証明書とサーバー秘密鍵をインストールします。その後、Flask を使用してmTLS認証用のWeb サーバーをCloud Functions上に構築します。参考記事: https://tex2e.github.io/blog/python/mtls
まとめ
プロジェクトを通して得られた学び
機械学習モデルのクラウドデプロイについて
ローカル環境でのモデル構築は経験があったものの、それをどのようにしてシステムに組み込むのか、具体的な方法については知識がありませんでした。Vertex AI Endpointsを利用することで、モデルをAPIとして公開し、他のシステムから利用できる形にすることができました。この過程で、Flaskアプリケーションの作成、Dockerコンテナ化、そしてVertex AIへのデプロイという一連の作業を経験し、機械学習モデルをクラウド上で運用するための実践的なスキルを習得できました。
セキュリティを考慮した設計の重要性
カメラデバイスからCloud Functionsへ画像を送信する際の認証方式を検討する中で、セキュリティの重要性を改めて認識しました。当初は認証なしで実装していましたが、これでは誰でも画像をアップロードできてしまうため、mTLS認証を実装することにしました。mTLS認証の仕組みや、クライアント証明書とサーバー証明書の違い、そしてMicroPythonでの実装方法などを学習し、セキュアなシステムを構築するための知識を深めることができました。この経験を通して、単にシステムを構築するだけでなく、セキュリティを考慮した設計の重要性を痛感しました。
Pythonの標準ライブラリのありがたみ
MicroPythonでの開発を通して、Pythonの標準ライブラリのありがたみを実感しました。ESP32ではMicroPythonを使用しましたが、標準ライブラリの数が限られているため、Pythonでは当たり前に使えていたライブラリが使えませんでした。例えば、base64エンコードやJSONの操作など、Pythonでは標準ライブラリで簡単にできたことが、MicroPythonでは追加のライブラリを探したり、自作したりする必要がありました。この経験を通して、標準ライブラリの存在がいかに開発効率を高めているかを実感するとともに、組み込み環境での開発においては、リソースの制約の中で最適なライブラリを選択する能力が重要であることを学びました。
Google Cloudサービスを使った感想
ドキュメンテーションが充実していることを実感
今回のプロジェクトを通じて、Google Cloudサービスのドキュメンテーションが非常に充実していることを実感しました。開発を進めるにあたり、過去に同様の開発を行った方のブログ記事を参考にすることが多くありました。しかし、クラウドサービスの進化は早く、記事によっては過去のバージョンのサービスを使用しており、そのままでは同じコードで実装できないケースが多々ありました。そのような場面で、Google Cloudの公式ドキュメントは非常に役立ちました。各サービスの機能やAPIについて詳細かつ最新の情報が提供されており、ブログ記事との差異を容易に埋め合わせることができました。特に、バージョン間の変更点や非推奨となった機能に関する情報は、迅速な問題解決に繋がりました。
コーディングに集中しやすい
例えば、転倒検知モデルの構築の際にCloud Functionsのようなサーバーレスサービスを利用することで、インフラの管理やサーバーの設定に煩わされることなく、コードの記述と実行に専念できました。このように、Google Cloudサービスは、開発者がそれぞれの専門分野に集中し、効率的にシステムを構築できるよう支援してくれると感じました。
今後の展望
実際に、医療・介護現場へ導入するためには、下記の課題を克服する必要があると考えました。
- 転倒検知の精度向上
現在のモデルは、特定の条件下では誤検知や検知漏れが発生する可能性があります。医療・介護現場では、高い精度が求められるため、①より多くの学習データを用いてファインチューニングを行うことや、②最新の論文をサーベイしながら最良の深層学習モデルを選択することで、精度改善が見込めます。
- プライバシーへの配慮
カメラ画像には個人情報が含まれるため、画像の匿名化や暗号化などの対策が必要です。また、システム利用者の同意を得るプロセスや、データ管理に関する規約を整備する必要があります。これらの対策により、システム利用者からの信頼を得ることが、医療・介護現場への導入には不可欠だと考えました。
- システムのリアルタイム性の向上
現在のシステムでは、転倒発生から通知までに数秒の遅延が生じる可能性があります。医療現場では、迅速な対応が求められるため、この遅延を最小限に抑える必要があります。そのためには、エッジデバイス側で推論処理を行い、クラウドへの依存度を下げることでリアルタイム性を向上させることができます。しかし、この方法では更に高スペックなエッジデバイスを導入する必要があり、コストが大きいため慎重に検討する必要があります。
著者プロフィール
大岩
慶應義塾大学卒業後、同大学院にて統計学を専攻。2023年より Furious Green でインターンを開始し、Google Cloud を用いたサービス開発を一から学ぶ。クラウド技術とデータ分析を活用し、DXの推進に貢献することを目指している。
山本
慶應義塾大学大学院を卒業。2023年よりFurious Greenにてインターンを開始し、現在は業務委託として勤務。「自然言語処理」×「マーケティング」に関心がある。