次元削減手法比較:PCA・t-SNE・UMAPどの手法を使うべき?
1.はじめに
近年の機械学習において、数百から数千といった高次元データを扱うことは日常的になりました。こうしたデータから本質的な情報を保ちつつ、扱いやすい低次元空間へ縮約する手法が次元削減です。
次元削減を行う主な目的は以下の2点です。
- データの可視化
私たち人間は4次元以上を直感的に認識できません。データを2次元(多くても3次元)に落とし込むことで、データの分布や構造を視覚的に捉えることが可能になります。 - 次元の呪いの解消
次元の呪いとは、高次元空間において発生する「計算コストの増大」や「距離の無意味化」といった問題の総称です。適切な次元削減によりこの影響を抑制することは、機械学習モデルの学習効率化や、クラスタリング精度の改善などに直結します。
本記事では、代表的な手法である PCA (主成分分析)、t-SNE、UMAP の特徴を解説します。それぞれの仕組みを理解し、状況に応じて最適な手法を選択するための判断軸を明確にすることが本記事のゴールです。
2.代表的な手法
ここでは、現在広く使われている3手法、PCA・t-SNE・UMAP について、その直感的な仕組みと特徴について解説します。以下のイラストは、それぞれのアルゴリズムがデータをどのように圧縮するかを端的に表しています。
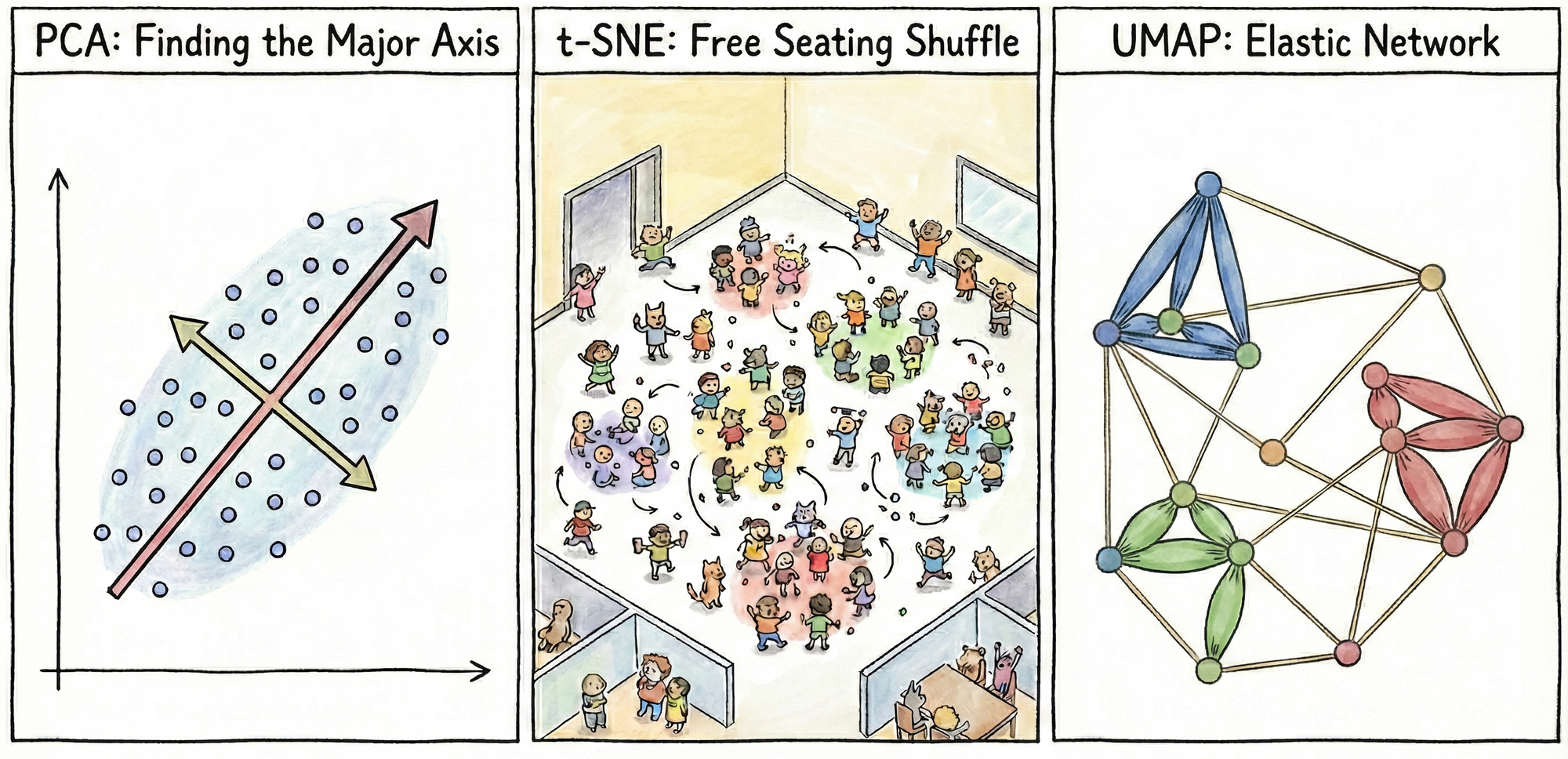
- PCA (Principal Component Analysis)
PCAは日本語では主成分分析として知られる古典的な線形手法です。
左図のように、データのばらつき(分散)が最も大きい軸を見つけ、その軸へデータを射影します。空間全体を回転させて最も情報量の多い方向から眺め直すイメージです。
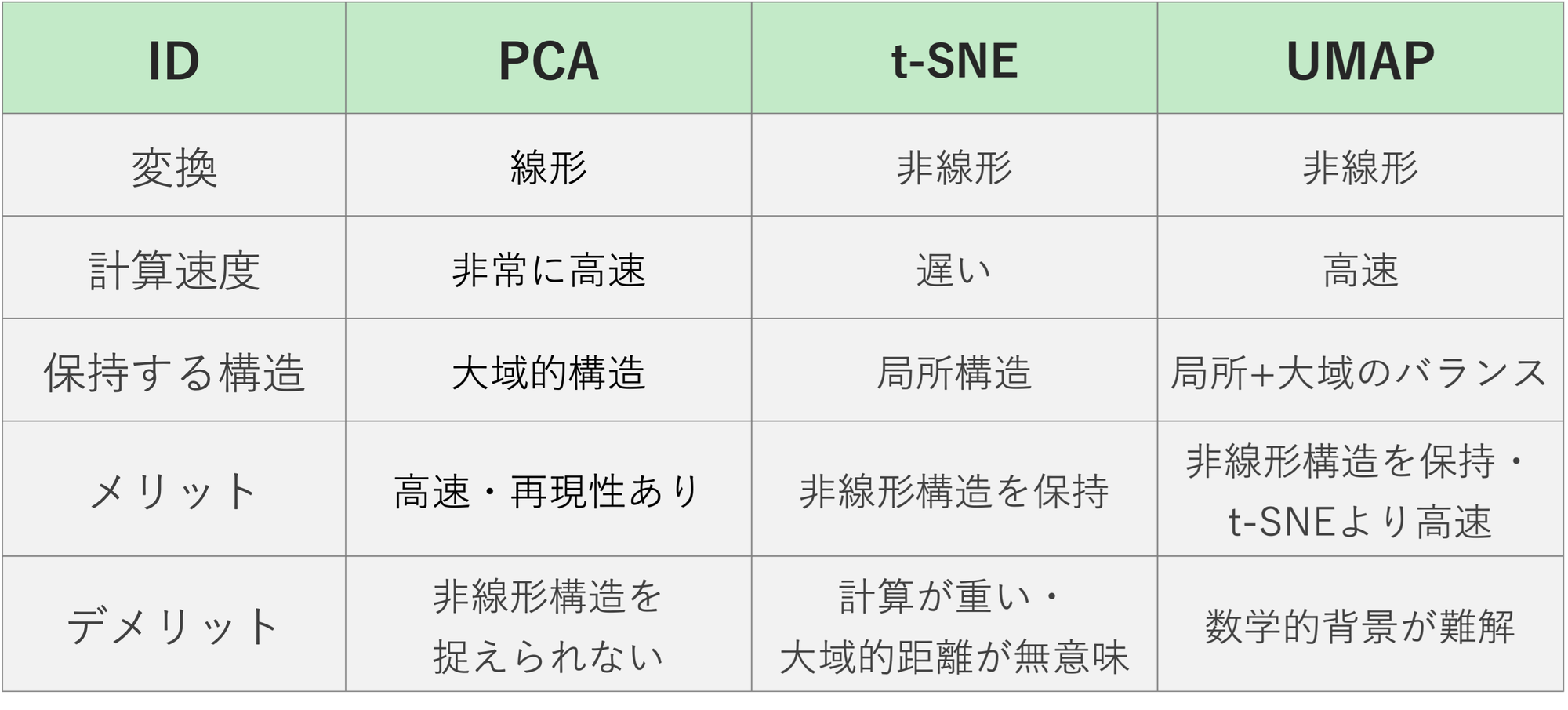
・メリット: 計算が高速、大域的な距離関係を保持、再現性がある
・デメリット: 非線形構造を捉えられない、分離性能は低い
- t-SNE (t-Distributed Stochastic Neighbor Embedding)
t-SNEは高次元空間で近くにあるデータが、低次元空間でも近くにあるように配置する非線形手法です。 データ点間の距離を確率分布に変換し、元の空間と圧縮後の空間での分布のズレを最小化するように学習します。
イメージとしては、中央図のように、自由な席替え(Free Seating Shuffle)と捉えられます。仲の良い友達が近くに集まり、そうでない者は遠ざかるように、全員が居心地の良い場所が見つかるまで何度も移動を繰り返す様子に似ています。
・メリット:非線形圧縮、局所構造の保持
・デメリット:計算に時間がかかる、大域構造が失われる
- UMAP (Uniform Manifold Approximation and Projection)
UMAPはリーマン幾何学と代数トポロジー理論を応用した非線形手法です。データ点同士の近さをもとにネットワークを作り、そのつながりが低次元空間でもなるべく同じになるように配置します。
イメージとしては、右図のようなゴム紐で結ばれたネットワーク(Elastic Network)として捉えられます。近い点同士は強く結ばれて離れにくく、遠い点同士は弱く結ばれ、自然な形に広がります。
t-SNEよりも大域構造を保ちやすく、計算も高速なため、現在ではデファクトスタンダードとして広く使われています。
・メリット:非線形圧縮、計算が高速、新規サンプルの埋め込みに対応
・デメリット:クラスタの密度情報が保存されない
各手法の比較
3.検証・実験設定
ここでは実際のデータ分析を通して手法の比較を行います。 検証の目的別に可視化性能の確認とクラスタリングの前処理としての有効性検証の2つを行いました。
本記事で使用した検証用コード(MNISTの可視化、Livedoorニュースのクラスタリング)は、以下のリポジトリで公開しています。 実験環境の再現や、パラメータ調整の参考としてご活用ください。
3.1. 画像データの可視化 (MNIST)
高次元データが人間にとって理解しやすい形(2次元)にどうマッピングされるかを確認します。
実験設定
- データセット: MNIST (手書き数字画像 0〜9)
- 次元数: 784次元 (28 × 28 ピクセル) → 2次元へ圧縮
- データ数: 10,000枚

結果
各手法による2次元プロットの結果は以下の通りです。
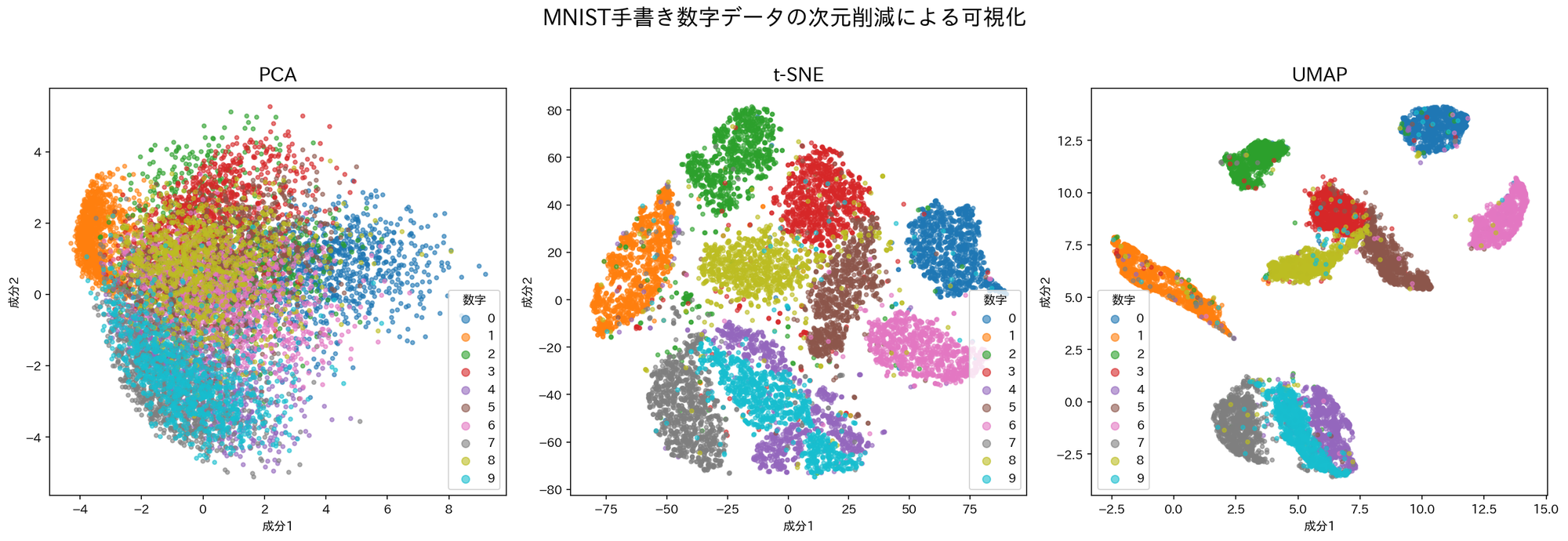
- PCA (左図): 全体がひとつの大きな塊になり、数字ごとの境界が曖昧。線形変換のみでは、手書き文字のような複雑な非線形構造を十分に分離できていないことがわかる。
- t-SNE (中央図): PCAとは対照的に、数字ごとに明確なクラスタに分かれている。分離性能は非常に高いが、大域的な位置関係(どの数字が似ているか)は読み取りにくくなっている。
- UMAP (右図): t-SNE同様に高い分離性能を示しているが、t-SNEに比べて各クラスタがよりギュッと凝縮されている。また、中央部の3, 5, 8や下部の4, 7, 8など、似た形状の数字が近くに配置される傾向があり、大域的な構造も保持しようとする特性が見て取れる。
3.2. クラスタリングの前処理 (ライブドアニュース)
次に、次元削減をクラスタリングの前処理として利用した場合の有効性を検証します。
実験設定
- データセット: ライブドアニュースコーパス (日本語ニュース記事)
- クラス数: 9カテゴリ(IT, スポーツ, 芸能など)
- データ数: 7367記事
- ベクトル化: Google Embedding API (
gemini-embedding-001) を用いて768次元のベクトルに変換 - タスク:
- 768次元のベクトルを各手法で圧縮
- PCA: 768次元→50次元
- t-SNE: 768次元→3次元 (高速な近似手法の制約上3次元まで。4次元以上に削減するには厳密解を求める必要があり、数十分かかる)
- UMAP: 768次元→10次元
- 圧縮後のデータに対して K-Means でクラスタリングを実行
- 768次元のベクトルを各手法で圧縮
- 元のカテゴリラベルとの一致度を評価
- 評価指標
- ARI (Adjusted Rand Index): 正解ラベルとのペアの一致度。-1〜1の値を取り、1に近いほど良い。
- NMI (Normalized Mutual Information): 正解ラベルとクラスタ結果の間でどれだけ情報量を共有しているか。0〜1の値を取り1に近いほど良い。
結果と考察
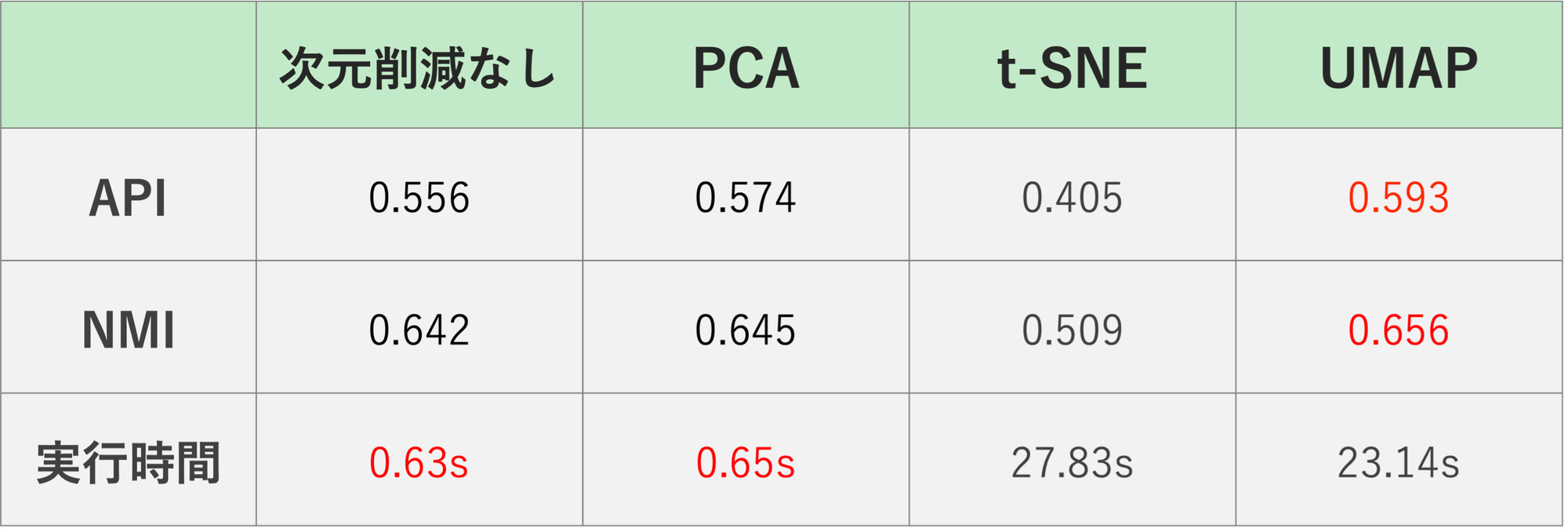
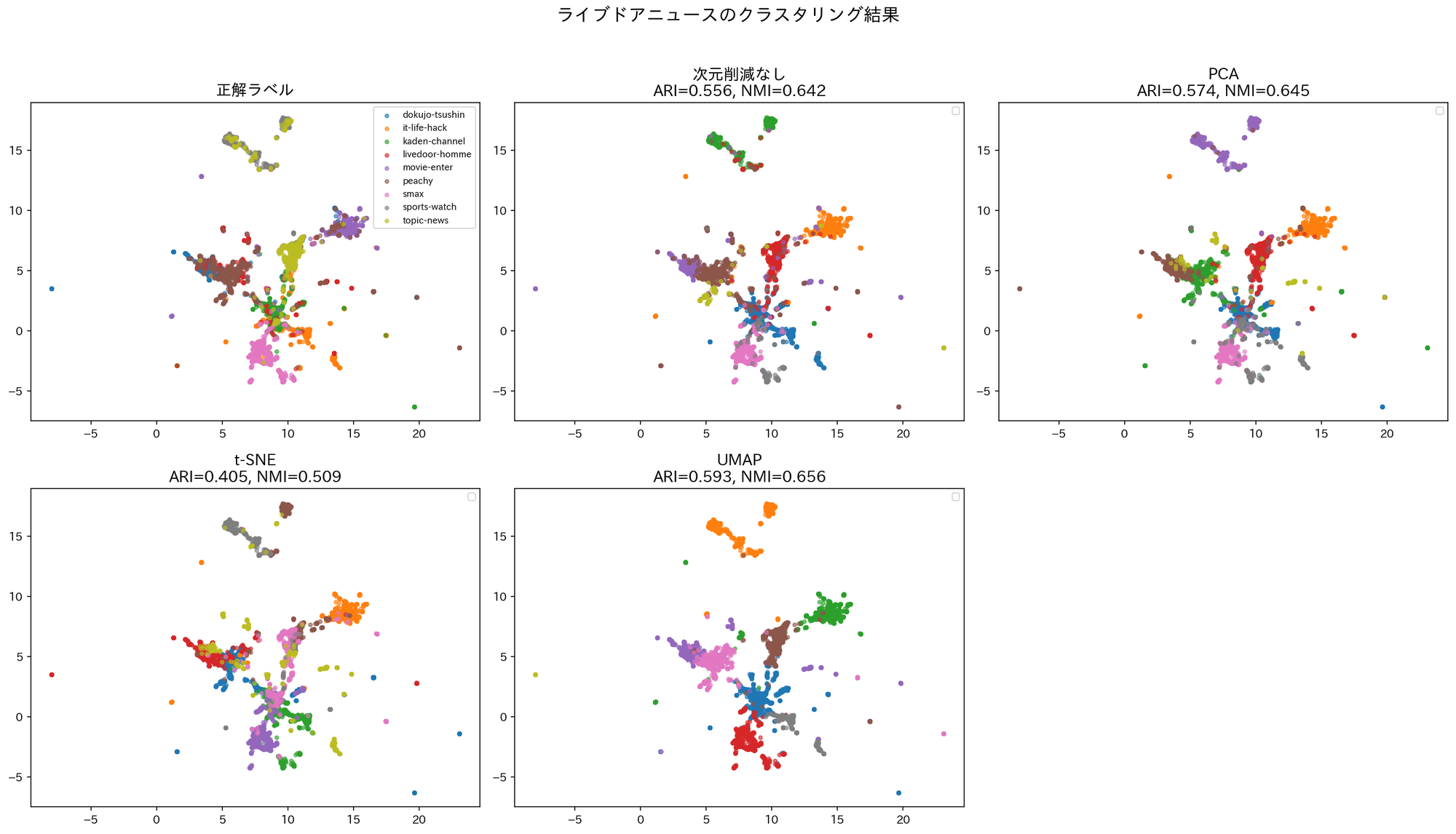
ARI, NMI, 実行時間をまとめた表、およびクラスタリング結果の可視化(可視化用にはUMAPを使用)は以下のようになりました。
以上の結果から、各手法について次のように考察できます。
1. PCAはとりあえずの選択肢として優秀
K-Means自体の計算負荷が高くない今回のケースでは、「次元削減なし」と「PCA」の実行時間はほぼ変わらなかった。しかし、PCAを通すことでノイズが除去され、ARI/NMIともにスコアが向上している。とりあえず次元削減手法を適応して様子を見たいという場面では、PCAがファーストチョイスとなりえる。
2. t-SNEはクラスタリングの前処理には不向き
t-SNEは可視化では優秀だが、クラスタリング精度はARI/NMIともに悪化した。 これは、高速化手法の実装(Barnes-Hut法による近似計算)の制約上、2〜3次元への圧縮が限界だったことが原因と考えられる。PCA(50次元)やUMAP(10次元)に比べ、t-SNEのみ3次元まで情報を削ぎ落とさざるを得ず、クラスタリングに必要な特徴量が欠落してしまったと考えられる。
3. 精度を追求するならUMAP
UMAPはPCAに比べて計算時間を要するが、ARI/NMIともに最高値を記録した。 これはUMAPが非線形な多様体構造をうまく捉え、K-Meansが分類しやすい特徴を提供できたためである。計算リソースや時間に余裕があり、とにかくタスクの精度を高めたいという場合はUMAPがベストチョイスと言える。
4.まとめ
以上の実験結果から導き出した、技術選定の指針は以下の通りです。
- 可視化 → t-SNE または UMAP
明確に分離されたクラスタを作れるt-SNEは、データの違いを強調するのに最適。一方で、クラスタ同士の距離感(大域構造)も正しく表現したい場合はUMAPが適している。 - コスト重視 / ベースライン作成 → PCA
計算が瞬時に終わり、パラメータ調整も不要。まずはこれでノイズを除去して基準スコアを作成し、開発の出発点とするのが定石。 - 精度重視 → UMAP
計算時間は多少かかるが、PCAでは捉えきれない非線形構造を抽出可能。クラスタリングなどの下流タスクにおいて、精度の最大化を狙うならUMAPの採用を推奨。 - t-SNEの注意点
可視化専用と割り切るのが無難。計算アルゴリズムの制約上、高次元への圧縮には不向きであり、無理に次元を落とすと重要な情報が失われるため、機械学習の前処理としての利用は非推奨。
📊 データ活用を次のフェーズへ進めませんか?
膨大なデータの中に眠る「本質的な価値」を見つけ出すには、適切な手法選定と深い専門知識が不可欠です。
「自社の高次元データをどう可視化すべきか?」「クラスタリング精度を向上させる最適な手法は?」など、データサイエンスに関するお悩みや、社内トレーニングのご相談を随時承っております。
「まずは話を聞いてみる」
私たちの専門知識を、貴社のビジネス加速にお役立てください。ぜひ、どのようにお力添えできるか一緒に話し合いましょう。